 pancho's blog
pancho's blog
쿠버네티스 클러스터 구축
도커/쿠버네티스를 활용한 컨테이너 개발 실전 입문
Google Kubernetes Engine 환경 설정
- GCP에서 제공하는 관리형 쿠버네티스 서비스를 GKE(Google Kubernetes Engine)를 사용
- GKE는 쿠버네티스의 개발을 주도하는 구글이 제공하는 가장 널리 사용되는 관리형 쿠버네티스 서비스 중 한가지.
Step1. GCP 계정을 만든다.
Step2. 프로젝트를 만든다.
- 프로젝트명은 중복 가능성이 있기 때문에 프로젝트를 유일하게 식별하기 위해 프로젝트 ID가 추가로 설정된다.
Step3. GCP SDK를 설치한다.
- https://cloud.google.com/sdk/docs/install
- 설치가이드에 gcloud 명령어를 바로 사용할 수 있게 path에 추가 해주는 스크립트를 실행하게 되는데 실행 후
source ~/.zshrc를 통해 적용을 해주어야 사용 가능하다.Step4. 사용할 프로젝트를 설정한다.
gcloud auth logingcloud config set project [프로젝트이름]gcloud config set compute/zone asia-northeast3-a- 한국 리전이 asia-northeast3
Step5. 쿠버네티스 클러스터 생성
- 한국 리전이 asia-northeast3
- 클러스터를 생성할 때 옵션을 줄 수 있다. 클러스터를 생성할 때 옵션
- 책에서 사용한 옵션들
-
--cluster-version: 쿠버네티스의 클러스터 버전으로 책보다 내 클러스터 default 버전이 높기 때문에 클러스터 버전은 지정하지 않고 default를 사용한다. 클러스터 버전은 다음 명령어로 확인 할 수 있다.gcloud container get-server-config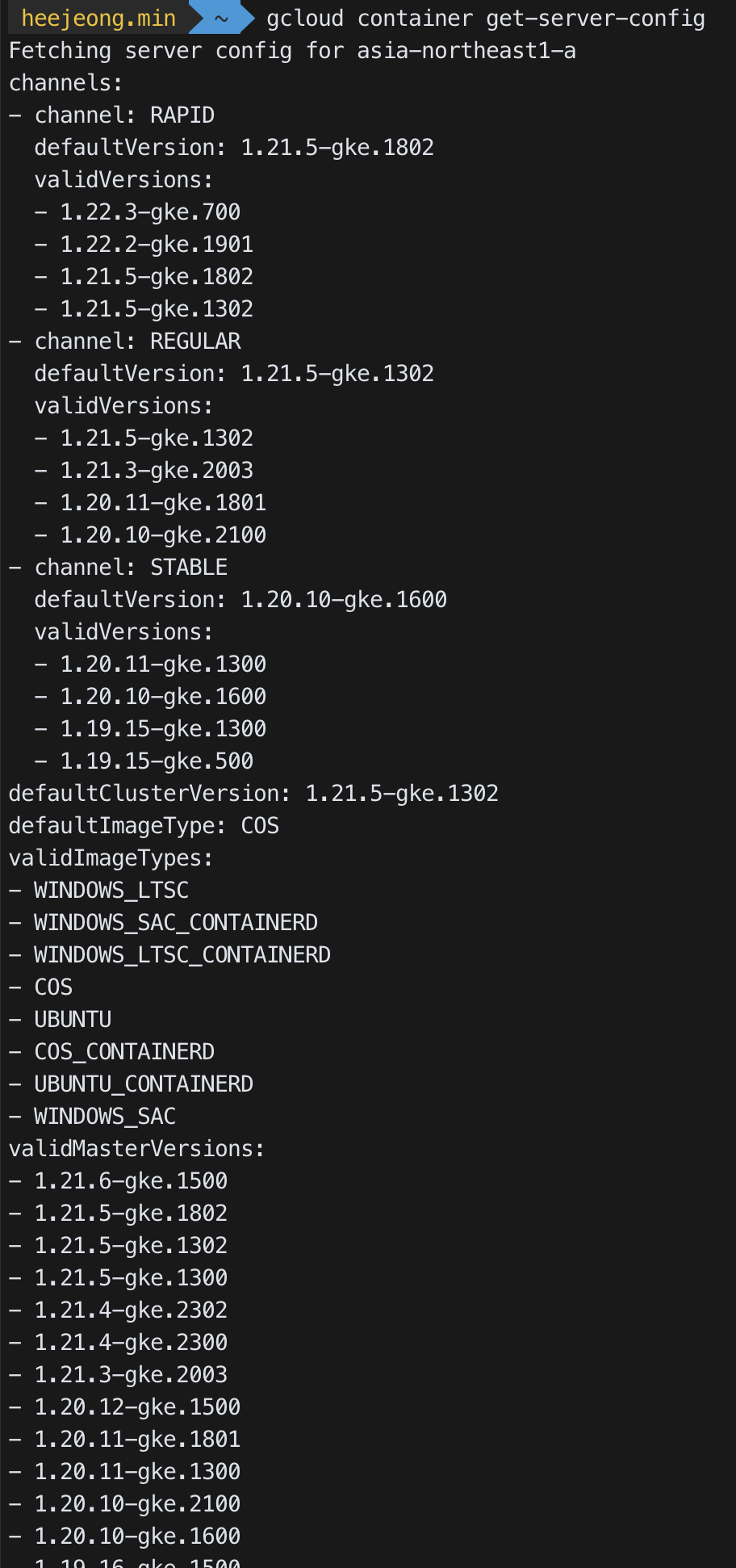
-
--num-node: 인스턴스의 수를 지정 -
--machine-type: 노드에서 사용할 컴퓨팅 머신을 지정하는데, default는 e2-medium 이다. 가능한 머신은gcloud compute machine-types list으로 확인 할 수 있는데 빌링 어카운트를 등록하고 실제 사용하려는 프로젝트에 연결을 시켜주어야한다.- 빌링 등록 후 프로젝트에 연결하는 방법
- 머신 종류
gcloud compute machine-types list를 사용하면 너무 길어서 파일에 저장하여 봄.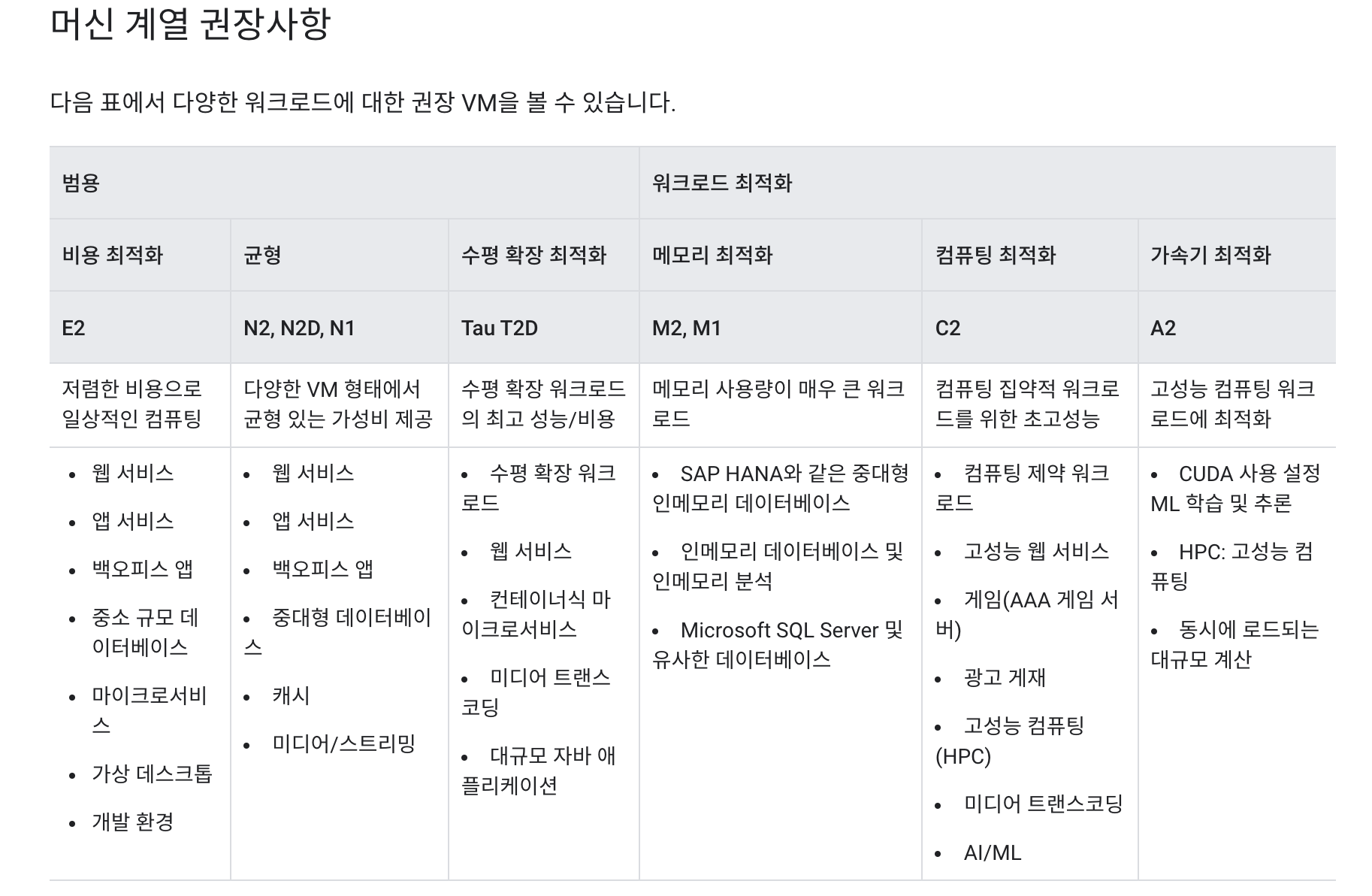
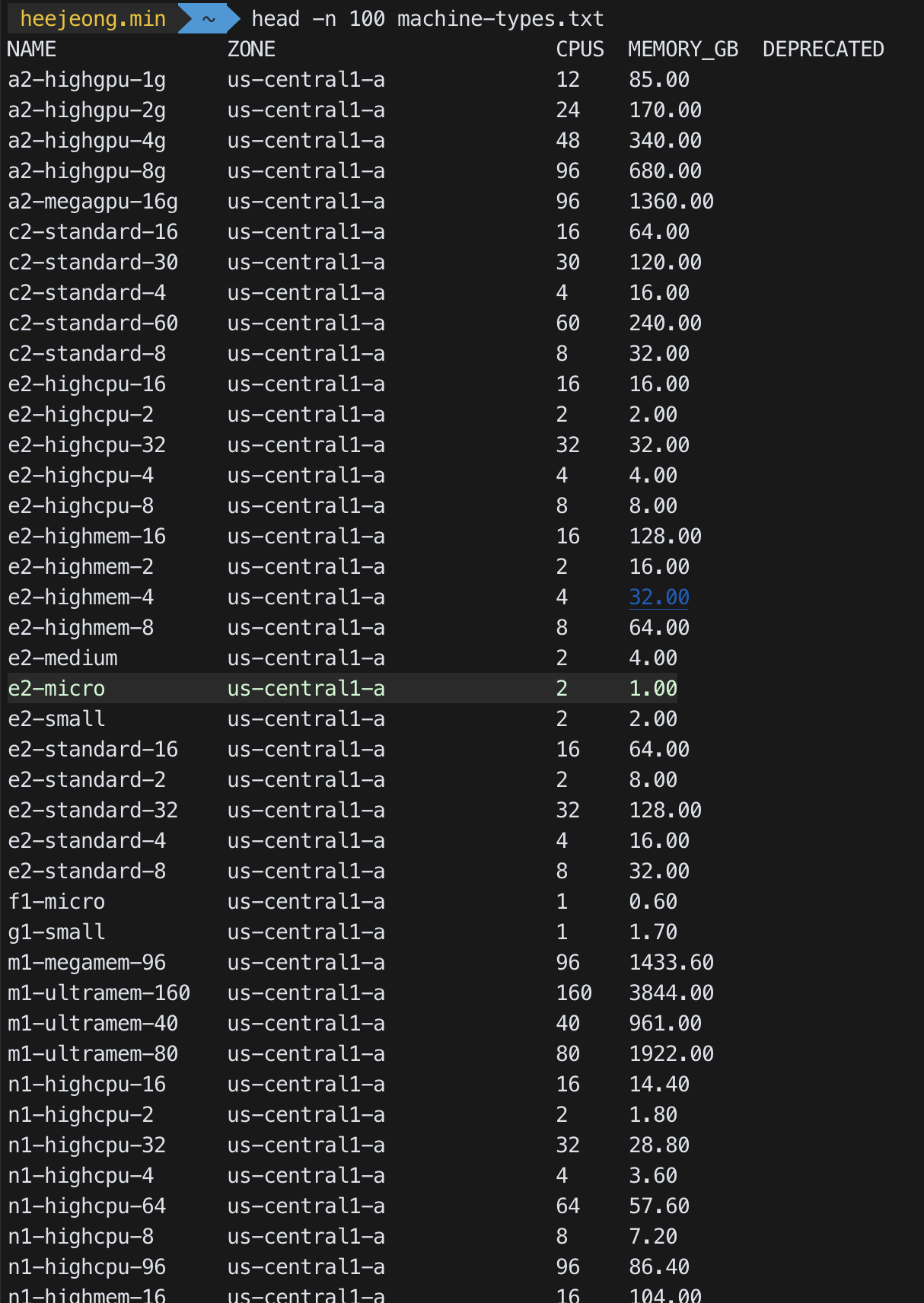
-
- 클러스터 생성 :
- 전제 :
- 프로젝트에 서비스 계정 이 생성되어 있어야 한다.
- 계정이 생성된 후 활성화 시켜주어야 한다.
- Kubernetes Engine API 활성화
- 클러스터 생성 (시간 좀 걸림)
gcloud container clusters create dooroomi --machine-type=e2-micro --num-nodes=3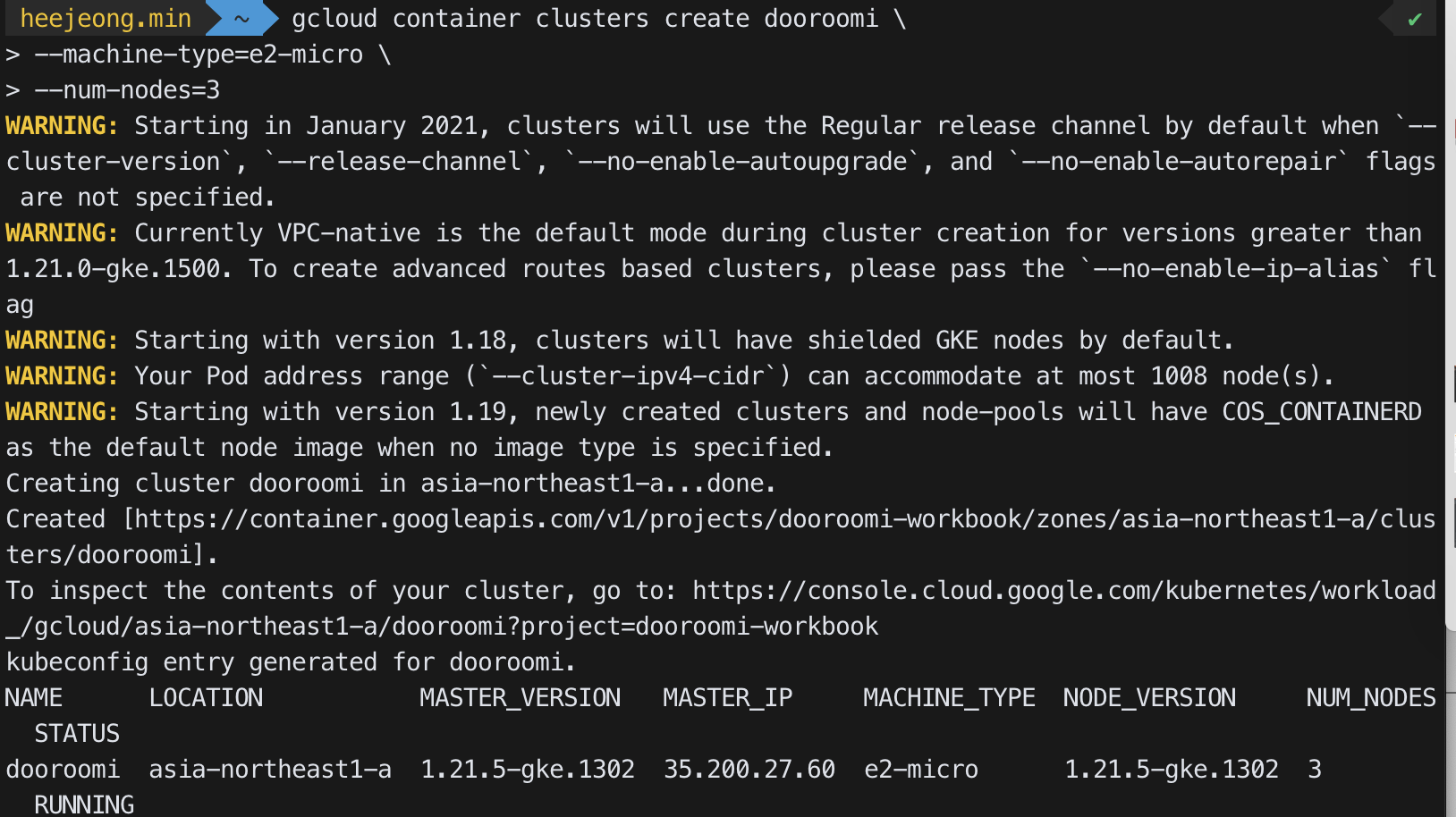
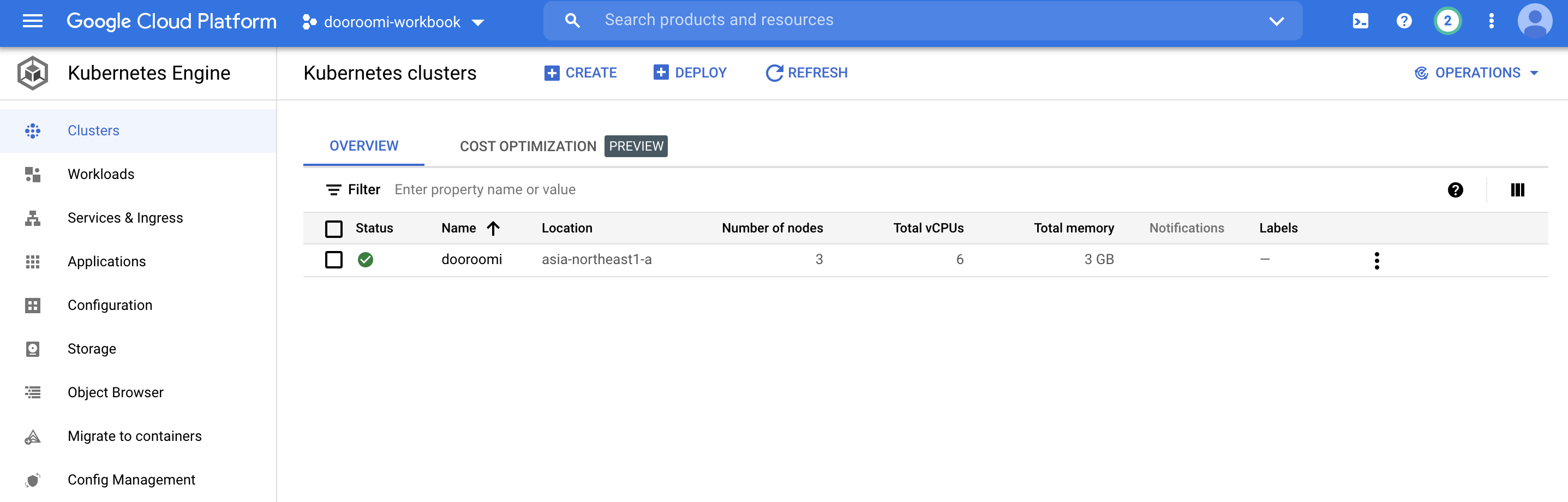
- 생성된 클러스터 조회하기
gcloud container clusters describe dooroomi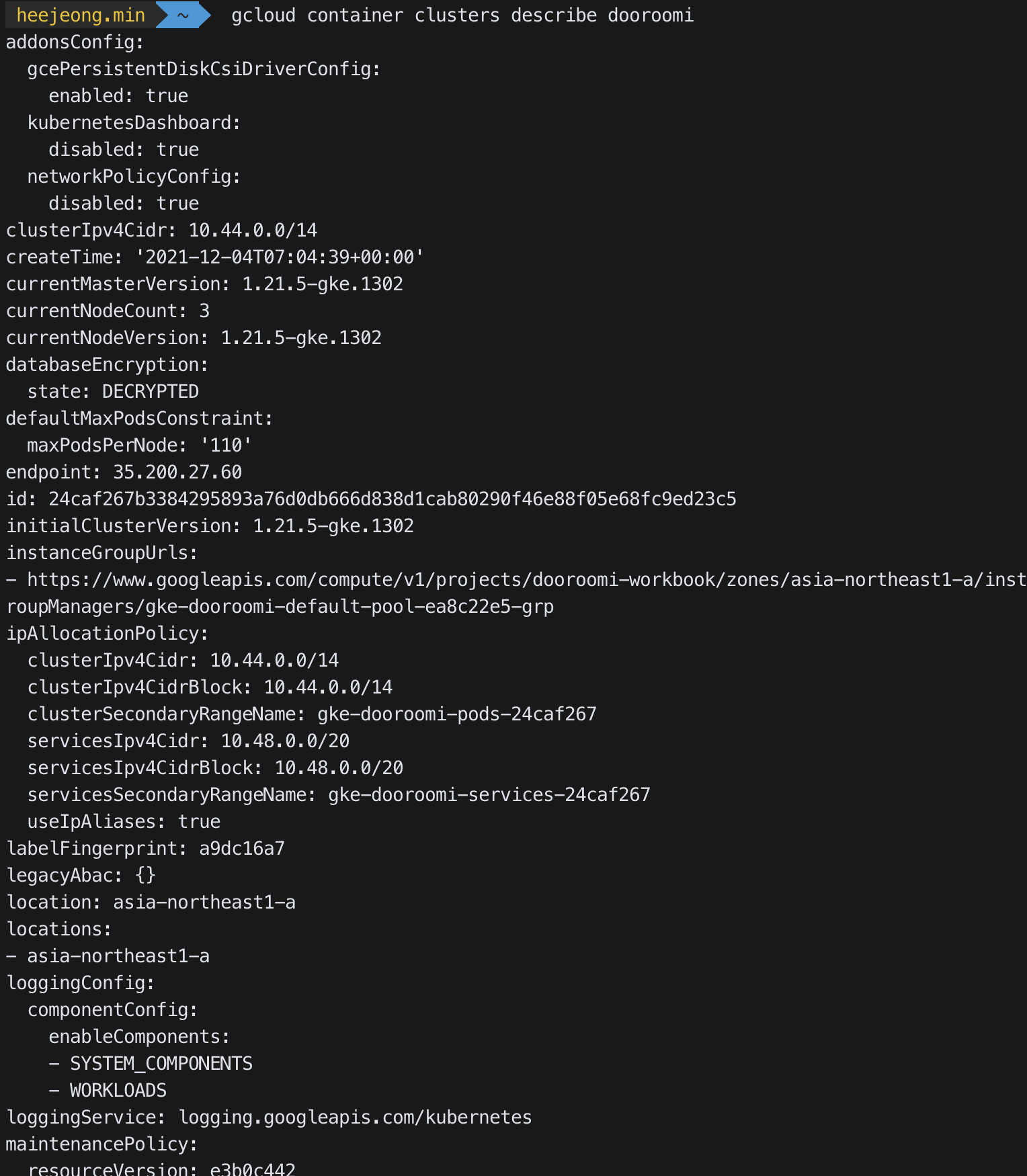
- gcloud로 클러스터를 제어할 수 있도록 kubectl에 인증정보 설정
gcloud container clusters get-credentials dooroomi
- 생성한 노드 검색
kubectl get nodes
- 쿠버네티스 API에 대한 프록시를 생성하면 새로 만든 클러스터의 대시보드도 볼 수 있다. (optional)
kubectl proxy
kubectx 와 kubens (https://github.com/ahmetb/kubectx)
- kubectx : context(cluster) 스위칭을 간편하게 할 수 있게 도와줌
kubectx: 전환 가능한 컨텍스트들을 보여줌kubectx [context name]: 지정한 컨텍스트로 스위칭kubectx -: 이전 컨텍스트로 돌아가기kubectx [alias]=[context name]: 컨텍스트에 별명주기
- kubens : kubernetest namespace 전환을 쉽게 할 수 있도록 도와줌
- 전제 :
Step 6. GKE에 애플리케이션 구축
Step 6-1. GKE에 MySQL을 마스터-슬레이브 구성을 구축 (optional due the gcp managed database)
- 퍼시스턴트 데이터를 다루는 컨테이너를 도커로 실행할 때는 데이터 볼륨으로 사용했다.
- 표준 데이터 볼륨은 컨테이너가 배포된 호스트에 위치해야하는데, 쿠버네티스에서는 호스트에서 분리할 수 있는 외부 스토리지를 볼륨으로 사용할 수 있다.
- 파드가 다른 호스트로 재배치 되어도, 외부 스토리지 형태의 볼륨은 새로 배치된 호스트에 자동으로 할당된다.
=> 호스트와 데이터 볼륨의 결합이 느슨해지기 때문에 퍼시스턴스 데이터를 다루는 애플리케이션을 컨테이너로 운영하기 쉽다. - 다음은 쿠버네티스 리소스가 이런 메커니즘을 구현하는데 사용되는 리소스이다.
- 퍼시스턴트볼륨(PersistentVolume : pv)
- 스토리지 자체로 보면된다. GCP에서는 GCEPersistentDisk 에 해당한다.
- 퍼시스턴트볼륨클레임(PersistentVolumeClaim : pvc)
- 추상화된 논리 리소스로, 퍼시스턴트볼륨과 달리 용량을 필요한 만큼 동적으로 확보할 수 있다.
- 예제 매니페스트
apiVersion: v1 kind: PersistentVolumeClaim metadata: name: myclaim spec: accessModes: - ReadWriteOnce volumeMode: Filesystem resources: requests: storage: 8Gi storageClassName: slow selector: matchLabels: release: "stable" matchExpressions: - {key: environment, operator: In, values: [dev]} - accessMode : 파드가 스토리지에 접근하는 방식
- ReadWriteOnce : 마운트(읽기/쓰기)될 수 있는 노드를 하나로 제한한다.
- ReadOnlyMany, ReadWriteMany에는 이러한 제한이 없지만, 플랫폼에 따라 사용할 수 없는 경우가 있으니 주의
- storageClassName : StorageClass의 종류로 어떤 스토리지를 사용할지 정한다. 파드는 퍼시스턴트볼륨클레임에 직접 마운트할 수 있으며, 데이터를 볼륨에 넣고 나면 파드를 정지하거나 다시 생성해도 애플리케이션의 상태가 유지된다.
- 스토리지클래스(StorageClass)
- 퍼시스턴트볼륨클레임에서 storageClassName의 속성값의 실체로 ‘표준’과 ‘SSD’가 있다.
- 생성할 스토리지 클래스 메니페스트를 다음과 같이 정의하고 생성해준다.
kubectl apply -f storage-class-ssd.yaml
kind: StorageClass apiVersion: storage.k8s.io/v1 metadata: name: ssd annotations: storageclass.kubernetes.io/is-default-class: "false" labels: kubernetes.io/cluster-service: "true" provisioner: kubernetes.io/gce-pd parameters: type: pd-ssd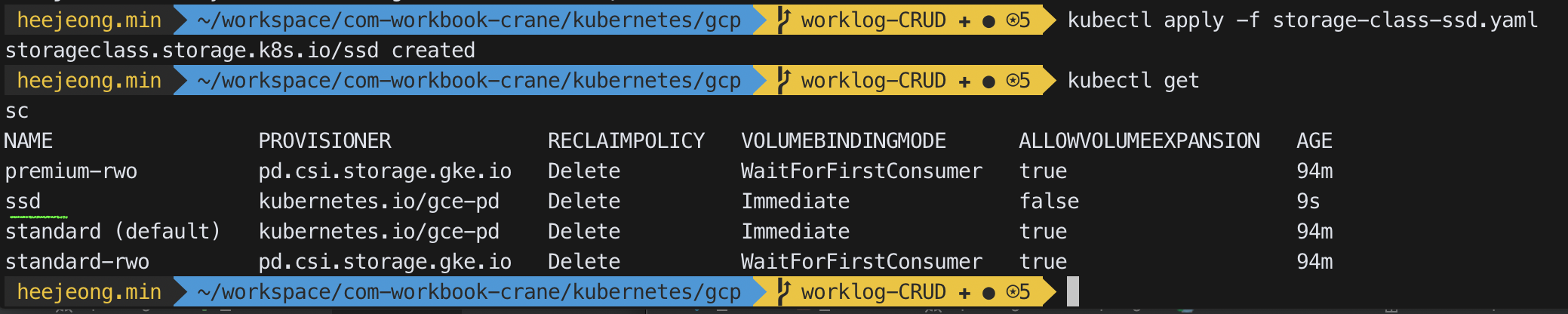
-
스테이트풀세트(StatefulSet)
Stage 디플로이먼트 스테이풀세 적합한 어플리케이션 stateless stateful 식별자 무작위 생성 부여 일련번호 생성 부여 - 디플로이먼트는 함께 포함된 파드 정의를 따라 파드를 생성하는 리소스로, 하나만 있으면 되는 파드 혹은 퍼시스턴스 데이터를 갖지 않는 상태가 없는 (stateless) 애플리케이션을 배포하는데 적합하다. 반면, 스테이트풀세트는 데이터 스토어처럼 데이터를 계속 유지하는, 상태가 있는 (stateful) 애플리케이션을 관리하는데 적합한 리소스이다.
- 디플로이먼트는 무작이로 생성된 식별자가 파드에 부여되지만, 스테이트풀세트는 pod-1, pod-2 와 같은 일련번호로 식별자를 생성하여 부여하며 파드 재생성/스케일링일대도 일련번호가 계속 이어져서 생성/부여되게 되어 있다.
- MySQL 마스터-슬레이브로 구성한 파드를 생성하는데 스테이트풀세트를 활용할 수 있다.
- 퍼시스턴트볼륨(PersistentVolume : pv)
-
이 단계를 optional 로 넣은 이유는 DB를 쿠버네티스를 활용하여 컨테이너라이즈 하는 것이 좋은지 아니면 클라우드에서 제공하는 관리형 데이터베이스를 사용하는 것이 좋은지에 대한 결정때문이다. 구글 클라우드 블로그 에 따르면 클라우드 서비스에서 제공하는 완전관리형 데이터베이스를 사용하거나, VM에 직접 구축하거나, 쿠버네티스를 사용하거나 하는 3가지 옵션이 있다고 소개가 되며, decision tree를 통해서 고려를 해 본 후 결정할 것을 이야기 하고 있다. 컨테이너 기술을 사용하였을 경우 전통적인 방법보다는 데이터 유실이 일어날 가능성이 더 높다는 것을 배제할 수 없음을 강조하고 있다.
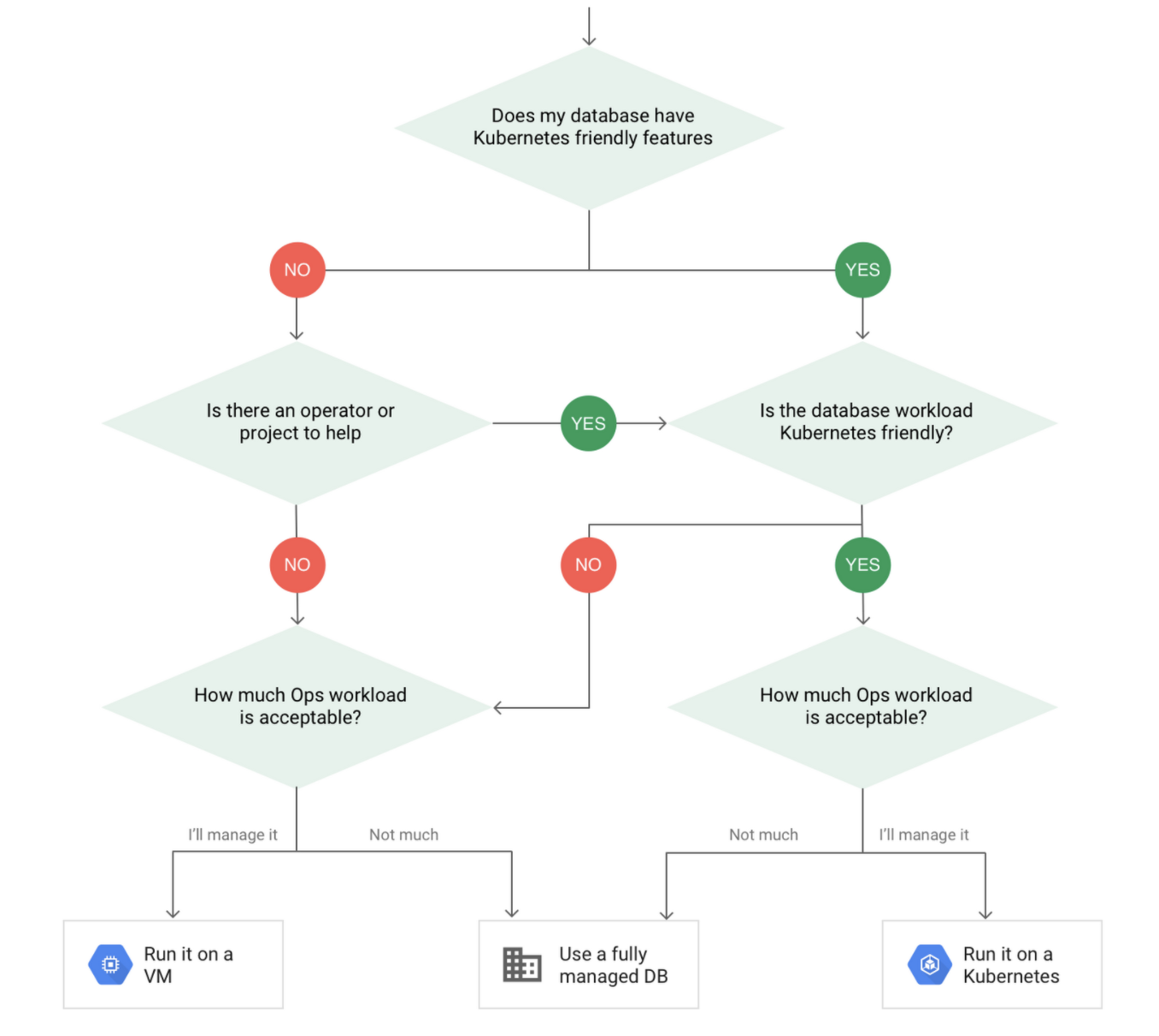
- 클라우드에서 제공하는 완전관리형 DB를 선택하고 어플리케이션만 쿠버네티스를 사용하도록 결정하였다. 이 결정을 할 경우
GKE에서 어떻게 관리형 DB에 접근할 수 있는지에 대한 글을 보며 DB를 생성한다.
- 하면서 중요했던점 (3번이 있으면 2번이 없어도 되는 것인지는 잘 모르겠어서 검증을 해봐야한다.)
- cluster가 떠 있는 동일 리전에 생성한다.
- 외부에서 접근 할 수 있게 VPC Network에서 방화벽 설정을 해준다. (로컬에서 바로 붙기 위해서)
- publicIP 를 사용할 수 있게 설정해준다. (내 로컬 PC의 아이피와 클러스터의 external IP를 /16 으로 설정해준다.)
- 하면서 중요했던점 (3번이 있으면 2번이 없어도 되는 것인지는 잘 모르겠어서 검증을 해봐야한다.)
- 클라우드에서 제공하는 완전관리형 DB를 선택하고 어플리케이션만 쿠버네티스를 사용하도록 결정하였다. 이 결정을 할 경우
GKE에서 어떻게 관리형 DB에 접근할 수 있는지에 대한 글을 보며 DB를 생성한다.
Step7. 파드 배포하기
아직 CI/CD를 설정하지 않았기 때문에 다음과 같이 진행해본다.
- 프로젝트 root에서 Dockerfile 생성
FROM openjdk:11 RUN mkdir /opt/app && apt clean && apt-get --allow-releaseinfo-change update && apt-get -y install netcat && apt-get clean COPY build/libs/com-workbook-crane-0.0.1-SNAPSHOT.jar /opt/app CMD ["java", "-jar", "/opt/app/com-workbook-crane-0.0.1-SNAPSHOT.jar"] - 프로젝트 빌드
./gradlew build - Dockerfile 이 있는 경로에서 이미지 빌드
docker build -t [이미지이름] .- 한가지 겪었던 당황스러운 점은 도커 이미지 빌드를 하면 apt-get update 에서 계속 invalide signature… 라는 에러가 나는데 여기저기 찾아보았고 결국 해결은 docker system prune으로도 안되어서 docker image ls 로 조회하여 지워도 되는 이미지들을 많이 지우고 나니 정상적으로 빌드가 되었다.
- 도커 허브로 푸시
docker push heejeong/crane - deployment manifest 작성
apiVersion: apps/v1 kind: Deployment metadata: name: crane-app labels: name: crane spec: replicas: 2 selector: matchLabels: app: crane template: metadata: labels: app: crane spec: containers: - name: crane image: heejeong/crane imagePullPolicy: Always ports: - containerPort: 8080 - service manifest 작성
apiVersion: v1 kind: Service metadata: name: crane-http labels: app: crane spec: type: LoadBalancer selector: app: crane ports: - name: http port: 80 targetPort: 8080 - Deployment, Service 생성
kubectl apply -f [파일이름]- 서비스의 External IP는 GKE에서 부하분산기를 생성하기때문에 조금 시간이 걸린다고 함.
- External API가 생긴것을 확인하면 curl 혹은 기타의 방법으로 연결가능 !!!