pancho's blog
pancho's blog
S3
Simple Storage Service
S3 : Simple Storage Service

- AWS 가장 오래된 서비스 중 하나 (S3, EC2, SQS)
- Serverless. 사용자가 구축이 따로 필요없다.
- 리전레벨 서비스로 이름은 전세계에서 유니크 하다
- Object Storage로 파일 일부 변경은 안되고, 전체 override 되는 형식이며 계층 구조 아님
- 저장하면 객체마다 접근 가능한 주소를 제공해 주는데 S3는 리전레벨 서비스 이지만, 주소는 Global하게 고유하다.
- 저장하는 객체 건당은 5TB 를 넘을 수 없지만 전체 데이터의 용량은 필요한 만큼 저장 가능
- 저장시 자동으로 3개의 AZ에 중복 저장하여 한 AZ에 저장된 데이터가 손상되어도 복구 할 수 있는 가용성이 높다.
- 파일이 업로드 되거나 등의 이벤트가 일어났을때 이벤트 트리거를 사용할 수 있다.
S3 엑세스 제어
- Default는 비공개 (버킷, 객체 및 관련 리소스 (수명주기 구성, 웹사이트구성 등등)
-
리소스 소유자가 액세스 정책을 작성하여 엑세스 권한을 부여할 수 있음. 하지만 애플리케이션의 데이터를 저장하는 경우 많기 때문에 대부분의 사용사례에서는 퍼블릭 엑세스 필요하지 않다.
AWS Identity and Access Management (IAM) 액세스 제어 목록 (ACL : Access Control List)
- 버킷 정책
- 필수 값 : Effect, Action, Resource
-
Resource 값의 구분자에 콜론이 3개 나오는 이유
arn:aws:s3**:::**examplebucket/*- arn : Amazon Reousrce Name
- arn:aws:s3: —> 여기까지는 prefix
-
::: —> :Region Code:계정명:
값이 생략된 형태인데, 이유는 오브젝트의 주소 값은 global 하게 unique하기 때문에 명시하지 않아도 추적이 가능
- 권한이 복잡해지면 관리가 힘들어지는데, 이때 사용할 수 있는것이 S3 엑세스 포인트라는 api라고 하고 다음을 지원한다고 함.
- 단일 사용자
- 애플리케이션
- 사용자들의 그룹 또는 애플리케이션
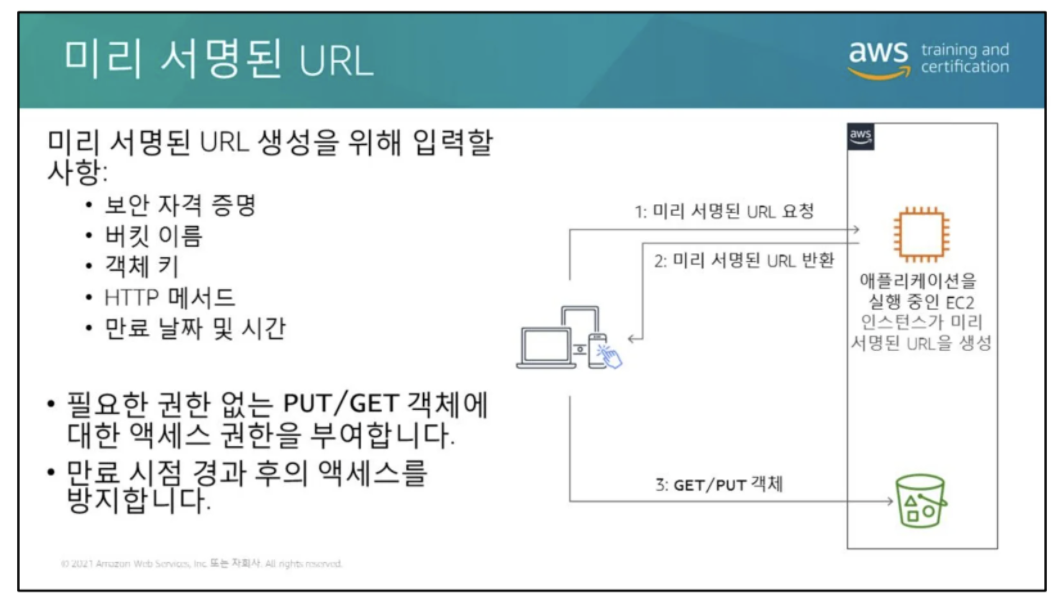
- 미리서명된 URL : 내가 가진 권한으로 다른사람이 일정 기간동안 접근할 수 있게 하는 기능

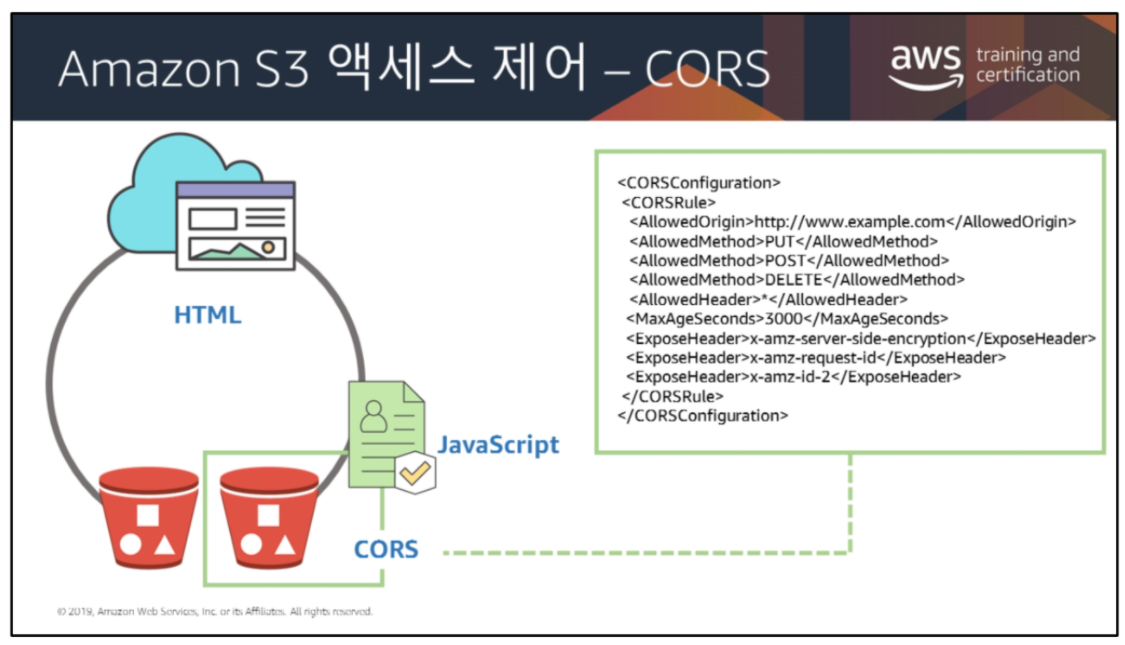
 https://docs.aws.amazon.com/AmazonS3/latest/dev/cors.html
https://docs.aws.amazon.com/AmazonS3/latest/dev/cors.html
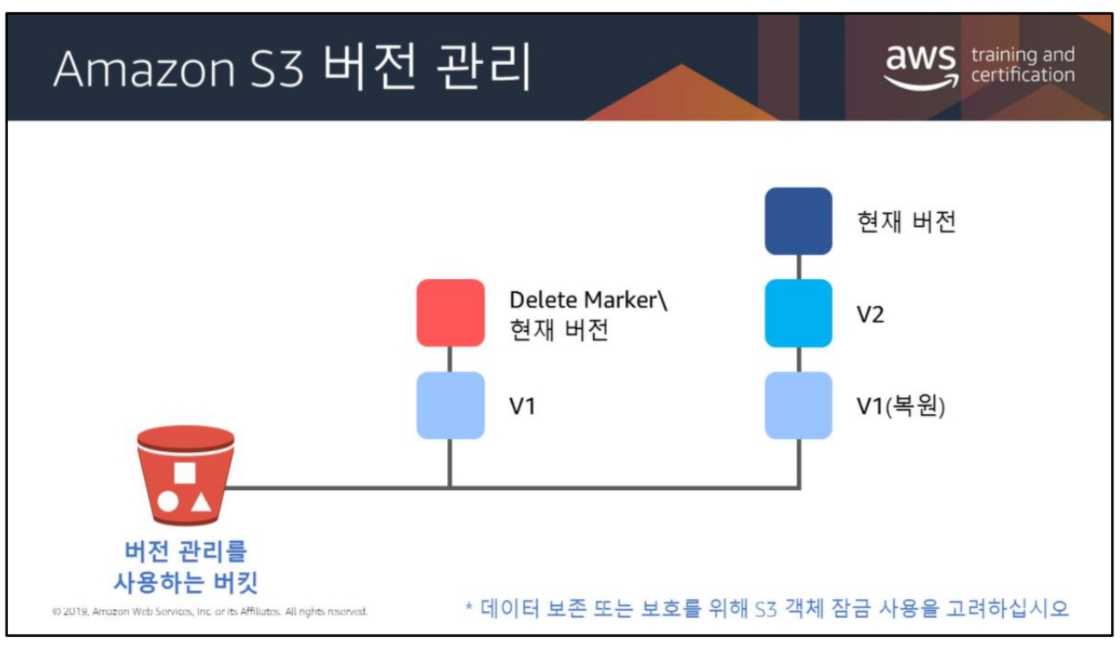
S3 버전 관리
- 버전 관리 옵션을 활성화 하면 파일 업로드 시 오버라이드 하지 않고 버전을 붙여서 관리를 해주고 이전 버전으로도 돌아갈 수 있다. 지우는 경우 soft delete 되기 때문에 지운파일도 남아있다.
- 다만 파일이 많이 늘어나기때문에 사용한 만큼 비용을 내는 점을 고려해야한다.
-
WORM (Write-Once-Read-Many)
- 데이터 보존 또는 보호를 위해 S3 객체 잠금을 사용할 수 있다. 실수로 덮어쓰거나, 삭제하는 일을 방지 할 수 있음. 일정 기간동안만 잠그는 것도 가능함.
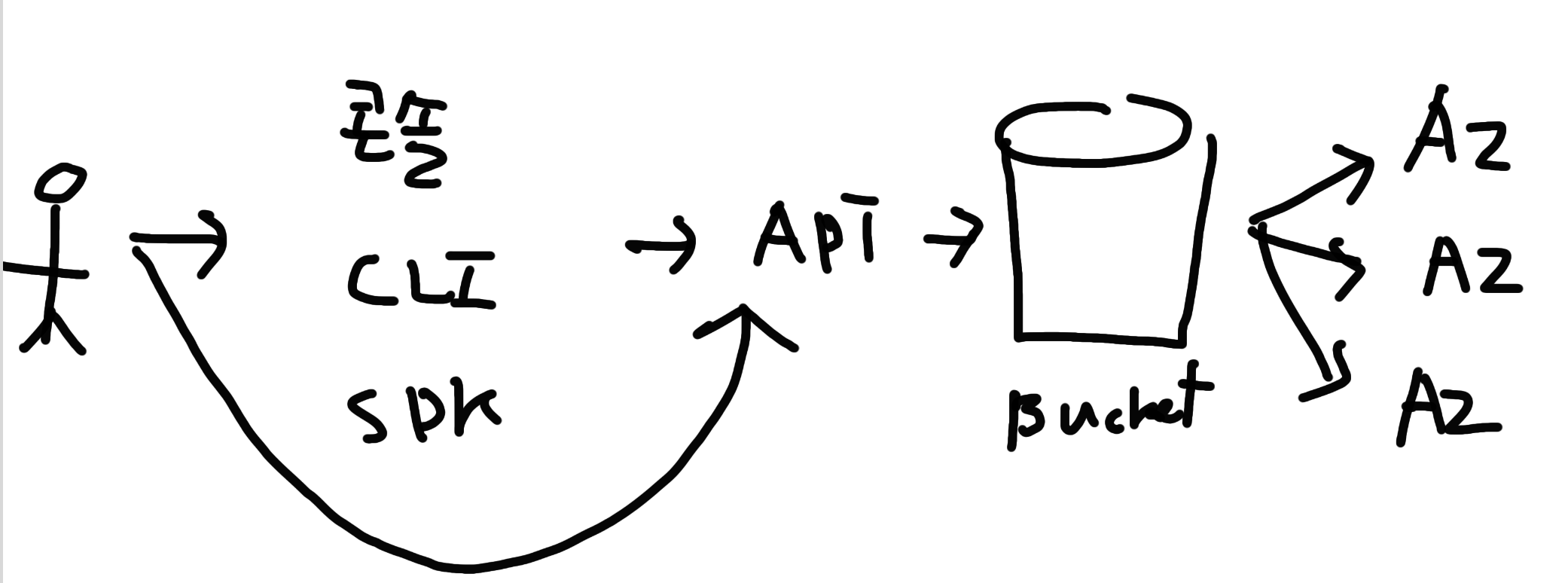
S3로 데이터를 이동하는 방법
- 데이터가 소량인 경우, 콘솔/CLI/API 사용 (버킷에 바로 올리는 것보단 많이 올림)
- 버킷에 바로 업로드 하는 경우 객체의 최대 크기는 160GB 제한.
-
- AWS DataSync
- 온프레미스 <> S3, Elastic File System (EFS)
- 오픈 소스 도구보다 10배 빠름
- 암호화처리, 스크립트관리, 네트워크 최적화, 데이터 무결성 검증 …
- NFS프로토콜 사용
- AWS Transfer for SFTP : SFTP를 통해 바로 S3로 업로드
- 멀티파트 업로드 가능 (하나의 객체를 쪼개서 올림)
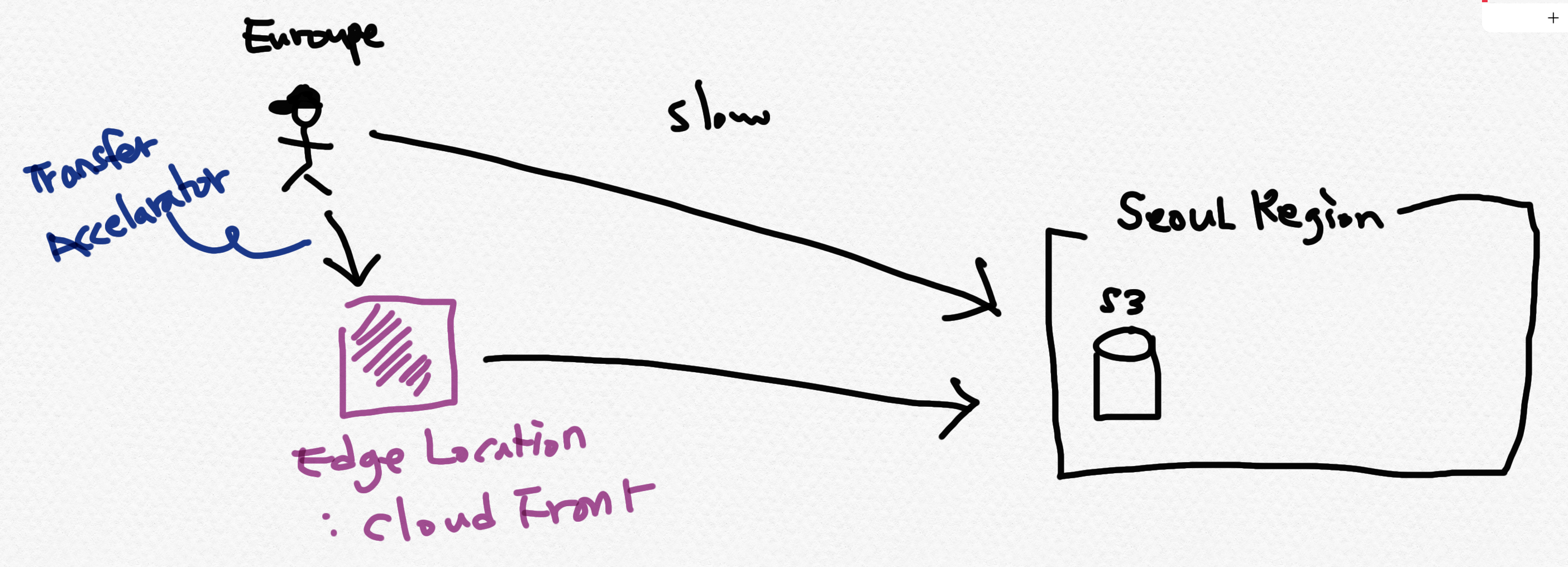
- Edge Location - CloudFront (아래 그림처럼 지리적으로 멀리 있는 고객이 upload, download 하는 경우 지연이 생길 수 있으니, Transfer Accelarator 옵션을 사용하면 edge location의 CDN 서비스인 cloud front를 사용할 수 있다.
- 대랑의 데이터 인경우 (데이터 센터 이전 등) : AWS Snowball, AWS Snowmobile
Create = upload = put
1) obj 크기 5T
2) multipart upload
3) sse (서버측 암호화)
4) MD5 “checksum”
Read = donwload = get
1) 다운로드
2) byte-range
3) select 기능 (csv, parquet) ⇒ sql query
4) key 기준으로 listing (prefix 사용) ex) “photo”로 시작하는 모든 오브젝트 가지고 오기
5) presigned url → 권한을 가진 사람이 접근 시간을 10초 ~ (?) 까지 정해놓고 다른 사람이 들어와서 볼 수 있게 만들어지는 방식
update x
delete
의도치 않은 삭제가 일어나는 경우를 대비한 versioning이 있다. versioning이 활성화되어 있으면 키별로 아이디가 붙는다. versioning을 하면 그 수만큼 사용한 금액이 나가니까 얼만큼 가지고 있을 건지에 대한 정책이 필요하다.

데이터를 올릴 시 비용을 아끼는법
아래처럼 호출하면 두번의 API가 호출되고 두번 비용이 나가게 된다.
이렇게 하면 한번 호출을 줄일수 있다!
s3.putobject("bucket", "key", File); //요청 1 돈
s3.put-metadata("bucket", "key", {"metat", "val"}); //요청2 돈
obj.addmetadata({meta:val})
s3.putobject("bucket", "key", obj)
if(isBucketExsit(bucketname)){ //버킷이 있는지 확인하는 콜에도 비용이드는데. 확인안해도 된다!!!
} else {
s3.makebucket(bucketname);
}
그냥 일단 putobject 하고 try catch!!
try {
s3.putobject();
} catch (NosuchBucketException e ) {
s3.makebucket!!!! //요청횟수 아낄 수 있다!!
}
Amazon S3 Glacier

- 장기 데이터 스토리지로 S3보다 훨씬 저렴하다. 리전마다는 금액이 다른데, 북미는 S3의 1/6, 서울은 1/5 정도라고 한다.
-
현재는 S3와 통합되었지만 원래는 다른 서비스였어서 부르는 저장되는 공간 및 데이터를 부르는 이름은 다르다.
S3 : bucket / object Glacier : Vault / archive
- 검색 옵션 : 비용이 높은 순이며, 신속검색을 원할 경우 차라리 S3로 옮긴 후 읽는 것이 낫다고 함.
- 신속 검색 : 1~5분
- 표준 검색 : 3~5시간
- 대량 검색 : 5~12시간
- 인텔리전트 티어링
- Standard, Standard IA간에 자주 쓰는 데이터는 Standard에 놓고, 자주 쓰지 않으면 Standard IA로 자동으로 옮겨주는 기능
- OneZone-IA (IA : Infrequent Access)
- Glacier에 존재하는 데이터이지만 잠깐 읽을 필요가 있을때 One Zone IA로 옮겨서 읽을 수 있다.
- 수명주기 정책
- 특정 주기 마다 S3 Standard → S3 Standard IA → S3 Glacier 로 옮겨가도록 설정 할 수 있다.
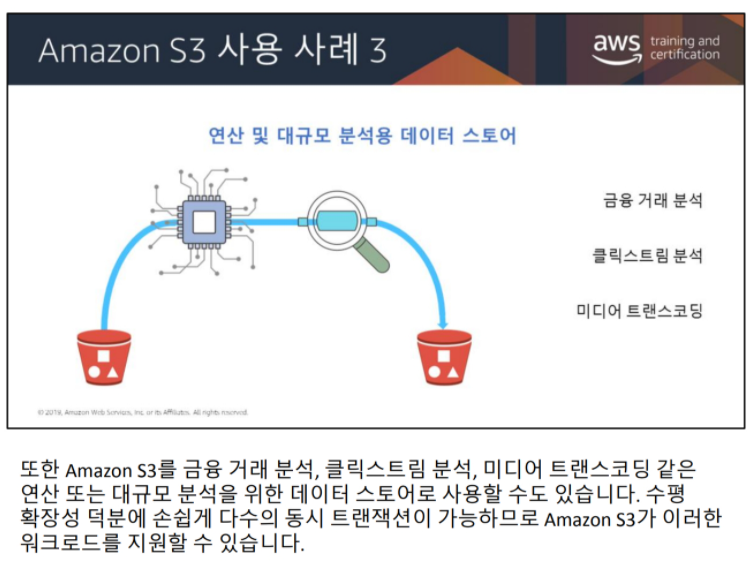
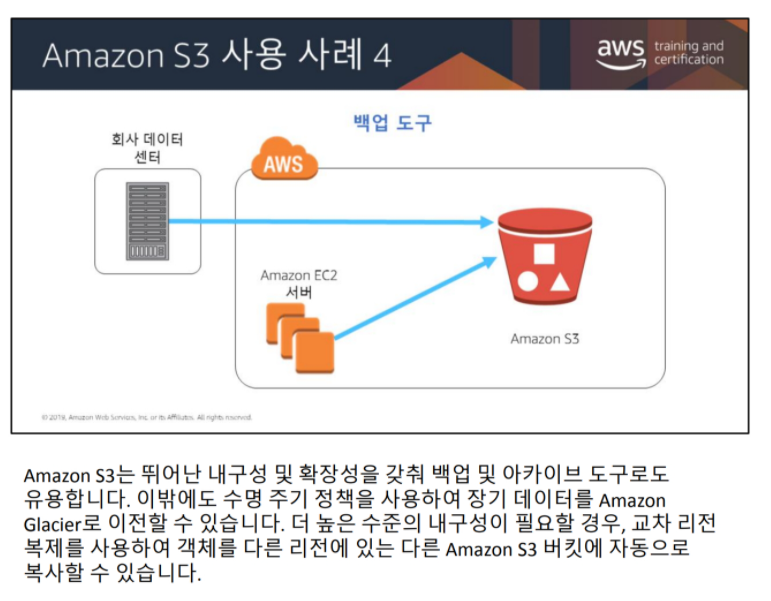
S3 사용 사례